
By: Wenda Wang, Mingxiao Huo, Eric Gao, Wen-Loong Ma
As AI models become more capable, industrial autonomy is becoming more tractable. The bottleneck, however, is no longer just high-level reasoning. The bottleneck is that legacy systems do not maintain stability under varying loads, do not adapt across tasks, and do not learn from failures. This article explains how Noble Machines is approaching these problems with a unified learning stack.
Real Work Is Different
In controlled demonstrations, it is tempting to focus on and grade a demo's success in isolation, on small portions of a problem, e.g., perception or task planning. In industrial settings, grading is done at the system level, and the metric is whether the job got done. The problem is even harder for mobile and general-purpose automation, where processes are physical, and almost everything has to happen simultaneously: maintaining balance under load, managing contacts, handling variability in object pose and presentation, and adjusting when things slip or the scene changes. A robot that executes one clean motion is no longer enough. It must remain useful through imperfection. In fast-paced, ever-changing environments, factory teams should not have to rebuild the workflow around the robot every time conditions change, and the systems should become easier to teach and adapt.
At Noble Machines, industrial autonomy means building machines that can be taught and execute useful factory tasks under dynamic loads, unpredictable variations, and shared human environments. That is why we built a robotic learning stack designed to address these three demands together: robustness to variation, adaptation across tasks, and learning from mistakes.
NVIDIA GTC served as an early test of that learning stack under live conditions.
What GTC Proved
At GTC 2026, Noble Machines used the same model to run two autonomous demos simultaneously across multiple Moby robots at both NVIDIAʼs and Noble Machinesʼ exhibits over four days. At NVIDIA's booth, Moby performed a long-horizon material induction task: picking payloads from various shelves, placing them into a tray, and then moving the tray aside. At the Noble Machines booth, Moby performed a material transfer task, moving pipes and wood from a shelf onto a cart. Both tasks were drawn from real customer workflows. Material induction ran for about two minutes per cycle, while material transfer ran for about thirty seconds per cycle. That mattered because the longer task created more opportunities for compounding errors, while the shorter task demonstrated whether the same system could adapt across different objects and task structures.
While a conference demo is not the same as industrial use, a live demo is informative if it exercises the right failure modes. These were not sanitized lab scenes. The robots operated in moving crowds, varying lighting, and narrow spaces. Both tasks were powered by a single end-to-end autonomy model trained on roughly 10 hours of demonstration data. The demonstrations were a public success, but more important was what they clarified.
First, useful behavior can now emerge with much less task-specific data than many people assume.
Second, live, unsanitized environments are becoming meaningful development settings rather than demo risks.
Third, the same learning stack can be adapted across distinct tasks without starting over each time.
Industrial autonomy is still a long way from being solved, but Noble Machines just moved the starting point forward.
A Learning Stack
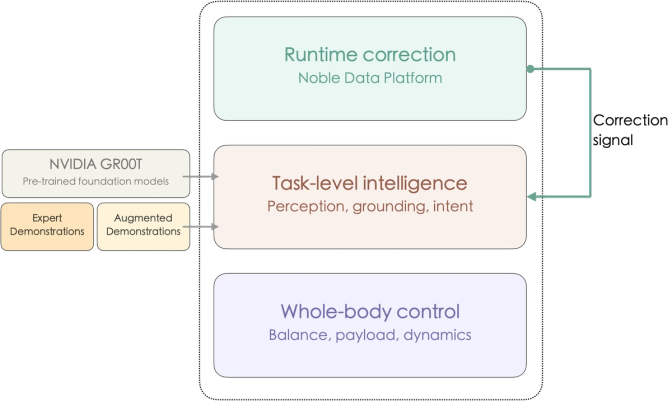
Noble Machines' learning stack is designed to assign the right problems to the right layers: whole-body control for physical stability, task-level intelligence for intent, and runtime correction for continuous improvement. At the bottom is a whole-body control foundation that handles balance, contact, payload, and stable motion under real constraints. Above that sits a task-level intelligence layer for perception, grounding, and intent-level action. Completing the stack is a runtime correction loop that turns interventions and failures into a targeted training signal. The design principle is to ensure each layer carries the right burden: the lower layer absorbs as much of the physical difficulty as possible, the middle layer stays focused on the task, and the system improves with use.
1. Body Control as The Foundation
Industrial tasks begin with the control of the body.
Long objects, awkward payloads, shifting contact, and shared workspaces place demands on the machine. Whole-body control of the legged system does more than keep the robot upright. It must simultaneously maintain stability under load, manage contact, reject disturbance, and continue executing when the scene is not exactly as expected. In industrial settings, those conditions are part of the job, not edge cases.
That is why Noble Machines' whole-body control is the physical foundation of the learning stack. In practice, industrial autonomy often breaks at the interfaces — between the controller and the task model, between hardware and software, between what the body can handle and what gets pushed up to the autonomy layer. Designing the machine, controller, and autonomy stack together is what allows those burdens to be absorbed where they belong. Operational payload is a good example. What matters is not whether the robot can lift a weight in isolation, but whether the machine can carry and manipulate a meaningful load while remaining capable enough for the task. That requirement not only shaped the controller. It drove actuator selection, mechanism design, body geometry, and the structural strength required across the machine.
See Real-World World-Building for more details.
As a single unified model, the WBC layer is designed to govern industrial tasks under varying loads rather than to pursue naturalness in human motion. The task model primarily uses the visual and task context. Payload variation, contact response, and changes in center-of-mass distribution must be resolved in real time at the control layer. By absorbing more of that burden in whole-body control, the system removes it from upper-layer task-level learning. As a result of this system, the demonstration data encodes task intent more directly, with less low-level compensation for payload shifts, center-of-mass changes, or disturbances, thereby providing the rest of the stack with a cleaner and more robust execution foundation.
2. Task-Level Learning on Top
Once the control foundation is strong enough, the role of the upper layer becomes clear.
This layer handles perception, grounding, and task-level action: what object to interact with, how to sequence the task, and how to respond when the scene changes. In practice, that layer may take the form of a vision-language-action model, a video-based task model, or another learned policy operating at the level of intent. Its job is task understanding, not low-level stabilization.
Foundation models like NVIDIA GR00T are valuable here because they provide a stronger starting point than building every capability from scratch. We then use teleoperated expert demonstrations to seed the task and amplify those demonstrations by roughly 10x through scene and background augmentation, combining video generation models with a custom segmentation pipeline that separates task-relevant objects from the background. That expanded dataset is used to train the baseline policy.
The starting point becomes more meaningful when the lower layer has already absorbed enough of the balance, contact, and payload problems. With a stronger whole-body control foundation underneath it, the task-level model can stay focused on the task instead of learning to compensate for instability from visual context alone. The resulting baseline was then evaluated under more challenging conditions—low light, external disturbance, and novel objects—to test whether it was learning the task rather than overfitting the scene. Better task-level priors matter most when the machine underneath them can execute reliably enough to make the resulting data useful.
3. Learning From Intervention
A baseline policy is only the beginning. Once it is running on the robot, the more valuable signal usually appears when the system struggles.
The failures that matter are usually concrete: misaligned shelves, imperfect contact, shifted objects, or recovery behaviors that are not yet good enough. The model runs, its behavior is supervised, and a human intervenes when it makes mistakes. Those interventions generate recovery data exactly where the policy is likely to fail. From there, the cycle is simple: run, intervene, retrain.
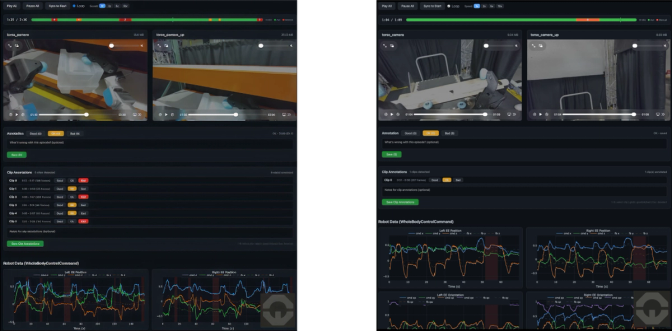
The Noble Data Platform makes that loop usable. It aligns video, proprioception, actions, force-related signals, task metadata, and rollout outcomes so that every intervention and failure can be traced back into a training example. That turns a mistake into a targeted training signal instead of just another bad run.
During four days of continuous operation at GTC, the correction loop ran twice. Each cycle involved roughly one hour of supervised deployment, during which operators intervened when the robot struggled. Those intervention clips — around ten minutes of targeted recovery data per cycle — became the retraining signal. The Noble Data Platform up-samples those segments during training, concentrating the signal on exactly the cases where the policy failed rather than treating all collected data equally. Twenty minutes of targeted correction data, drawn from two hours of live operation, was sufficient to deploy across both booths.
Once the baseline performs well on common cases, additional random demonstrations are less effective at improving it. The higher-value data is correction data on the cases that still break. That is what makes the stack improve through use.
Taken together, these three layers do more than organize the system. They create a division of labor that makes industrial autonomy more practical. Whole-body control accounts for the physical variation in the task. The task model stays focused on perception, grounding, and intent. Runtime correction turns failures into a targeted training signal. The result is a stack in which each layer carries the right burden, and the whole system improves with use.
What Changes
Beyond architecture, this changes the economics of skill acquisition.
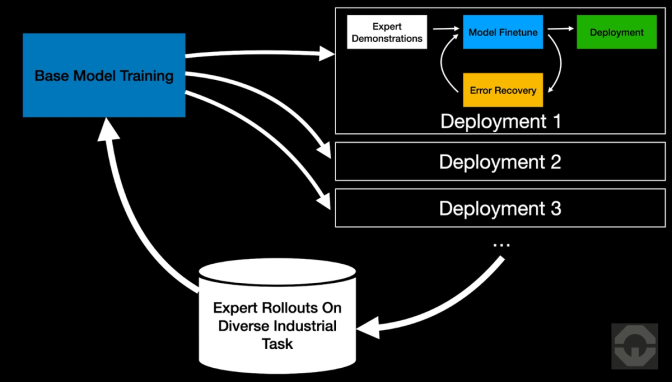
When whole-body control absorbs more of the physical difficulty, demonstrations become cleaner, and the task model needs less data to reach a usable baseline. The first deployment of a skill is cheaper. When runtime correction turns failures into a targeted training signal, the time from "this skill has a problem" to "this problem is fixed" compresses. As more skills are deployed, the base policy improves — so each subsequent skill still costs less. For industrial operations, that means skill deployment timelines shorten, response to line changes becomes faster, and the cost of training a new capability drops with each capability already learned.
Each deployed skill also becomes a source of training data. Once a skill runs reliably on the factory floor, the resulting expert policy can generate large volumes of additional trajectories across real industrial conditions — without relying on human teleoperation for every new example. That data feeds back into the base model, making it stronger and more general. A stronger base policy requires less task-specific data and fewer corrections to reach expert performance on the next skill. Faster skill acquisition leads to more deployments; more deployments produce better data; better data makes the next deployment faster. With the Noble Data Platform powering the learning loop, the flywheel compounds with each deployment rather than resetting, and the system becomes more data-efficient the more it is used.
What We Are Building Toward
Beyond the GTC demonstration, there remains a large gap between promising robot behavior and fully generalized industrial autonomy, especially under long-tail variation. Closing that gap will require tighter integration among control, learning, runtime correction, and the data systems that turn operation into improvement.
We are taking an iterative approach: reducing demonstration data requirements, improving post-training, broadening the range of tasks and environments the system is trained on, and continuing to leverage stronger foundation models and adjacent tools as they evolve.
Noble Machines' commitment is to build industrial autonomy that is easier to teach, more adaptable to real environments, and easier to improve through operation.